High-speed 3D geometrical modeling using Fast Level Set Method
The level set method, introduced by S. Osher and J. A. Sethian, has attracted considerable attention as a topology-independent approach to active contour modeling. By employing an implicit representation of contours, this method naturally handles topological changes such as merging and splitting. Level set-based techniques have been applied to a wide range of problems, including motion tracking, 3D geometric modeling, and simulations of crystallization and semiconductor growth. However, the computational cost associated with reinitializing and updating the implicit function is substantially higher than that of conventional active contour models, such as the “Snakes” model. To address this issue, we propose an efficient algorithm for the level set method, termed the Fast Level Set Method (FLSM). The main features of the proposed FLSM are as follows:
- The use of an extension velocity field, rapidly constructed via the Fast Narrow Band Method
- Frequent reinitialization of the implicit function at a low computational cost.
| Bunny (Stanford Univ.) | Wired basket |
Real-time tracking of multiple objects using Fast Level Set Method
| Simultaneous tracking of moving objects | Fast detection of moving objects |
| Skeleton extraction | Labeling |
Development of robust motion capture system using FLSM and stereo cameras
We are developing a novel motion capture system that employs the Fast Level Set Method in conjunction with multiple stereo cameras. This system is capable of simultaneously capturing the motion of multiple individuals, even in the presence of mutual occlusions. Experiments have been conducted to capture 3D motion data of traditional Japanese dance and clothing.
| Motion | Captured data |
| After texture mapping | Motion capture |
Papers
- Yumi Iwashita, Ryo Kurazume, Kenji Hara, Seiichi Uchida, Ken'ichi Morooka, and Tsutomu Hasegawa, Fast 3D Reconstruction of Human Shape and Motion Tracking by Parallel Fast Level Set Method, in Proc. IEEE International Conference on Robotics and Automation, pp.980-986, April 2008.
- Yumi Iwashita, Ryo Kurazume, Kenji Hara, and Tsutomu Hasegawa, Robust 3D Shape Reconstruction against Target Occlusion using Fast Level Set Method, Proc. The Second Joint Workshop on Machine Perception and Robotics, CD-ROM, 2006.
- Yumi Iwashita, Ryo Kurazume, Kenji Hara, and Tsutomu Hasegawa, Robust Motion Capture System against Target Occlusion using Fast Level Set Method, in Proc. IEEE International Conference on Robotics and Automation, pp.168-174, 2006.
- Yumi Iwashita, Ryo Kurazume, Tokuo Tsuji, Kenji Hara, and Tsutomu Hasegawa, Fast implementation of level set method and its realtime applications,in Proc. IEEE International Conference on Systems, Man and Cybernetics 2004, pp.6302-6307, 2004.
2D-3D alignment based on geometrical consistency
We propose a novel registration algorithm for aligning 2D images with 3D geometric models to enable realistic reconstruction of indoor scene settings. A common approach to estimating the pose of a 3D model in a 2D image involves matching 2D photometric edges with 3D geometric edges projected onto the image plane. However, in indoor environments, both the features that can be robustly extracted from 2D images and the jump edges present in 3D models are often limited. This constraint makes it challenging to reliably establish correspondences between 2D and 3D edges, often requiring manual initialization of the relative pose to a position close to the correct one. To address this limitation, the proposed method first performs a coarse estimation of the relative pose by exploiting the geometric consistency of back-projected 2D photometric edges onto the 3D model. Once a reasonable initial estimate is obtained, a refined edge-based optimization is applied for precise pose alignment. The effectiveness of the proposed approach is demonstrated through experiments using both simulated indoor scenes and real-world environments captured with range and image sensors.
| 2D-3D alignment | Alignment result |
Papers
Visual servo of mobile manipulator using redundancy
We propose a novel visual servoing technique based on the concept of redundancy. The core idea is the introduction of a virtual link that connects the camera to the target position. This virtual link functions analogously to a mechanical linkage, enabling the application of null-space operations—originally developed for controlling redundant manipulators—in the context of visual servoing.
| Tracking using redundancy | Visual servo using redundancy |
Place recognition using RGB-D camera and laser scanner
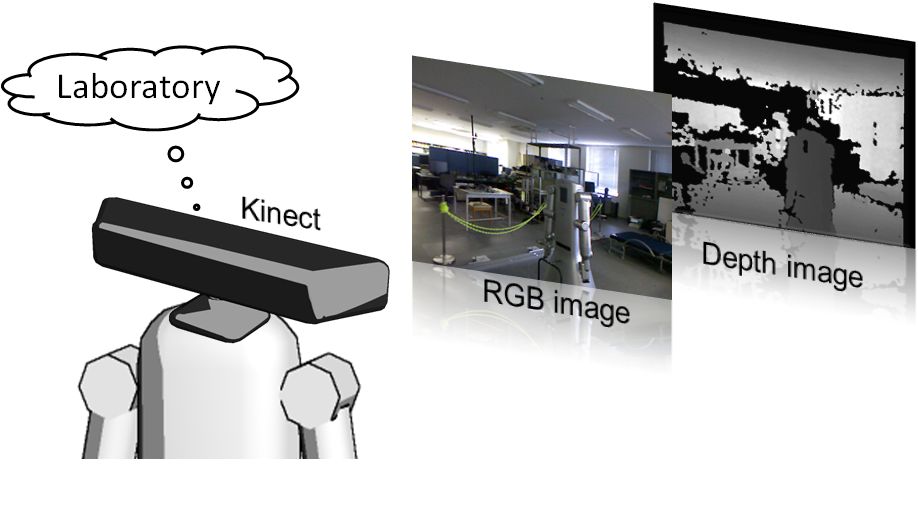
Categorizing places in both indoor and outdoor environments is essential for service robots to operate effectively and interact naturally with humans. In this study, we present a method for place categorization using a mobile robot equipped with an RGB-D camera (e.g., Microsoft Kinect) or a 3D laser scanner (e.g., FARO or Velodyne). Our approach converts depth and color images captured at each location into histograms of local binary patterns (LBPs), which are then dimensionally reduced using a uniform criterion. These histograms are integrated into a single feature vector, which is subsequently classified using a supervised learning method. For indoor environments, the proposed method successfully distinguishes between five place categories: corridors, laboratories, offices, kitchens, and study rooms. Experimental results demonstrate the effectiveness of the approach in accurately categorizing these locations. Furthermore, the method is extended to outdoor environments, including parking lots, residential areas, and urban spaces, showing its applicability to autonomous driving technologies.
| Place recognition using Kinect sensor |
|---|
 |
Database
corridors(255 Mbyte, 5 categories) 
|
genkiclub_f3_corridor_01, genkiclub_f4_corridor_01, w2_10f_corridor_01, w2_7f_corridor_01, w2_9f_corridor_02 |
kitchens(204 Mbyte, 8 categories) 
|
genkiclub_f3_kitchen_01, genkiclub_f3_kitchen_02, w2_10f_kitchen_01, w2_10f_kitchen_09, w2_9f_kitchen_01, w2_9f_kitchen_02, w2_9f_kitchen_10, w4_6f_kitchen_01 |
labs(583 Mbyte, 4 categories) 
|
hasegawa_lab, kurazume_lab, taniguchi_lab, uchida_lab |
offices(95 Mbyte, 3 categories) 
|
hasegawa_office, kurazume_office, morooka_office |
studyrooms(328 Mbyte, 8 categories) 
|
w2_2f_studyroom_01, w2_2f_studyroom_02, w2_2f_tatamiroom_01, w2_2f_tatamiroom_02, w4_2f_studyroom_01, w4_2f_studyroom_02, w4_2f_tatamiroom_01, w4_2f_tatamiroom_02 |
toilets(116 Mbyte, 3 categories) 
|
w2_10f_toilet_01, w2_2f_toilet_01, w2_9f_toilet_01 |
Papers
- Hojung Jung, Oscar Martinez Mozos, Yumi Iwashita, Ryo Kurazume, Local N-ary Patterns: a local multi-modal descriptor for place categorization, Advanced Robotics, Vol. 30, No. 6, pp.402--415, 2016, doi:10.1080/01691864.2015.1120242
- Hojung Jung, Oscar Martinez Mozos, Yumi Iwashita, Ryo Kurazume, The Outdoor LiDAR Dataset for Semantic Place Labeling, The 2015 JSME/RMD International Conference on Advanced Mechatronics (ICAM2015), Tokyo, Dec. 12.5-8, 2015
- Oscar Martinez Mozos, Hitoshi Mizutani, Hojung Jung, Ryo Kurazume, Tsutomu Hasegawa, Categorization of Indoor Places by Combining Local Binary Pattern Histograms of Range and Reflectance Data from Laser Range Finders, Advanced Robotics, Vol.27, No.18, pp.1455?1464, 2013
- Oscar Martinez Mozos, Hitoshi Mizutani, Ryo Kurazume, Tsutomu Hasegawa, Categorization of Indoor Places Using the Kinect Sensor, Sensors, Vol. 12, No. 5, pp.6695-6711, 2012
- Hojung Jung, Ryo Kurazume, Yumi Iwashita, Outdoor Scene Classification Using Laser Scanner, Proc. The Ninth Joint Workshop on Machine Perception and Robotics (MPR13), K-P-06, Kyoto, 2012.10.31-11.1(Best Poster Session Award)
Previewed Reality - Near-future perception system -
This research introduces a near-future perception system called "Previewed Reality." The system is composed of an informationally structured environment (ISE), an immersive VR display, a stereo camera, an optical tracking system, and a dynamic simulator. In the ISE, a variety of sensors are embedded to sense and record the positions of furniture, objects, humans, and robots, with this information stored in a centralized database. The position and orientation of the immersive VR display are continuously tracked using the optical tracking system. Based on this information, the system predicts potential future events using the dynamic simulator and generates synthetic images representing what the user is expected to see in the near future from their own viewpoint. These predictive images are overlaid onto the real-world view using augmented reality (AR) technology and presented to the user. By intuitively visualizing possible hazardous situations in advance, the proposed system enhances safety and facilitates smoother human–robot coexistence.
| Previewed Reality | Previewed Reality |
| Previewed Reality 1.0 and 2.0 | |
| Smart Previewed Reality | |
Papers
- Asuka Egashira, Yuta Horikawa, Takuma Hayashi, Akihiro Kawamura, and Ryo Kurazume, Near-future perception system: Previewed Reality, Advanced Robotics, Vol., No., pp.-, 2020, DOI:
- Yuta Horikawa, Asuka Egashira, Kazuto Nakashima, Akihiro Kawamura, Ryo Kurazume, Previewed Reality: Near-future perception system, 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2017), Vancouver, Canada, 2017.9.24-28, pp.370-375, 2017
- Yuta Horikawa, Asuka Egashira, Kazuto Nakashima, Akihiro Kawamura, Ryo Kurazume, Previewed Reality: Near-future perception system, Proc. The 13th Joint Workshop on Machine Perception and Robotics (MPR17), , Peking, 2017.10.16-17
Fourth person sensing / Fourth person captioning
"Fourth person sensing" and "fourth person captioning" are innovative concepts aimed at accurately recognizing the circumstances surrounding a user by integrating multimodal information from multiple perspectives. These concepts classify information sources according to n-person viewpoints: first-person (e.g., wearable cameras), second-person (e.g., cameras mounted on robots), and third-person (e.g., cameras embedded in the environment). By fusing data from all these sources, the system can comprehensively understand the current situation. This approach is analogous to how a reader of a novel can grasp the thoughts, emotions, and contexts of the protagonist, supporting characters, and other entities within the story—essentially adopting a "god’s-eye view." The goal of this research is to realize such an omniscient perspective for real-world perception.
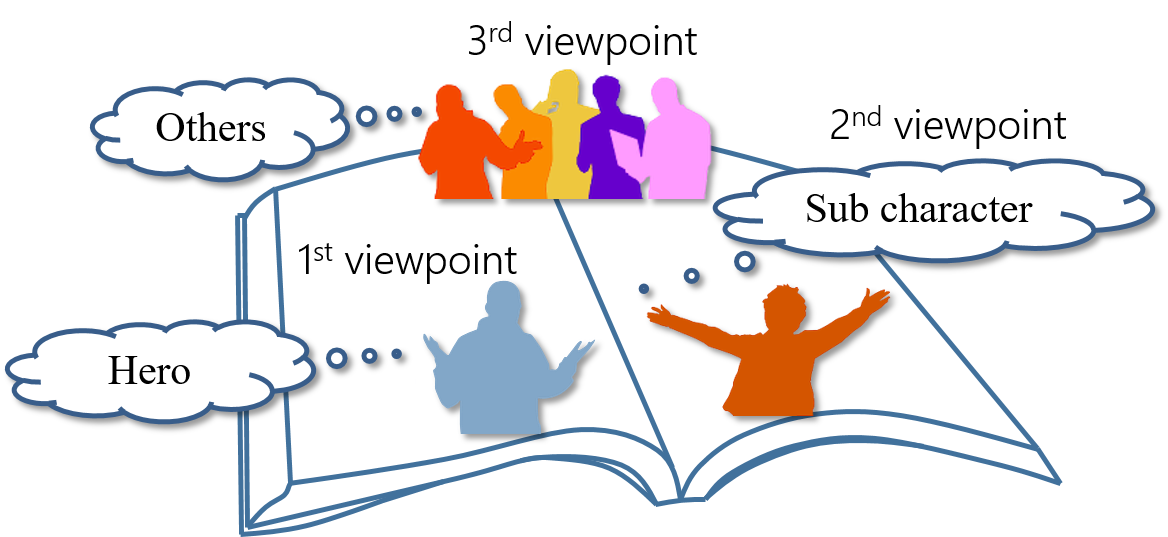 Fourth person sensing
Fourth person sensing |
 Fourth person captioning
Fourth person captioning |
Papers
- Kazuto Nakashima, Yumi Iwashita, Akihiro Kawamura, Ryo Kurazume, Fourth-person Captioning: Describing Daily Events by Uni-supervised and Tri-regularized Training, The 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC 2018), Miyazaki, 2018.10.7-10
- Kazuto Nakashima, Yumi Iwashita, Yoonseok Pyo, Asamichi Takamine, Ryo Kurazume, Fourth-Person Sensing for a Service Robot, Proc. of IEEE International Conference on Sensors 2015, pp.1110-1113, 2015
- Yumi Iwashita, Kazuto Nakashima, Yoonseok Pyo, Ryo Kurazume, Fourth-person sensing for pro-active services, Fifth International Conference on Emerging Security Technologies (EST-2014), pp.113-117, 2014
- Kazuto Nakashima and Ryo Kurazume, Describing Daily Events in Intelligent Space via Fourth-person Perspective Images, Proc. The 14th Joint Workshop on Machine Perception and Robotics (MPR18), PS2-1, Fukuoka, 2018.10.16-17