Fast Level Set Methodを用いた高速3次元幾何形状モデリング
高速で位相適応が可能な境界追跡法であるLevel Set Methodを高速に実現するアルゴリズムである「Fast Level Set Method」を提案し,高速な3次元幾何形状モデリング手法を開発しました.
| Bunny のモデリング (Stanford Univ.) | ワイヤーバスケットのモデリング |
発表論文
- 原 健二,岩下 友美,倉爪 亮,長谷川 勉,浦浜 喜一,球面レベルセット法と全方位複数輪郭抽出,情報科学技術レターズ,Vol.4, LI_002, (2005)
- 岩下,由井,倉爪,長谷川,Level Set Methodを用いた3次元物体形状の生成と追跡,日本機械学会ロボティクス・メカトロニクス講演会'03講演論文集, 2P1-1F-D7, (2003).
- 由井,原,査,倉爪,長谷川,解像度制御型Level Set Methodによる高速な位相適応型モデリング,第20回日本ロボット学会学術講演会予稿集,2A12, (2002).
Fast Level Set Methodを用いた複数移動物体の実時間同時追跡
「Fast Level Set Method」を用いて,複数の重なり合う移動物体の実時間同時追跡を実現しています.
| 複数物体の同時追跡 | 高速輪郭抽出 |
| スケルトン抽出 | 移動物体追跡 |
発表論文
- 岩下 友美,倉爪 亮,辻 徳生,原 健二,長谷川 勉,Fast Level Set Methodを用いた複数移動物体の3次元追跡,日本ロボット学会誌,Vol.23, No.7, pp.813-820, (2005)
- 倉爪,由井,辻,岩下,原,長谷川,Fast Level Set Methodの提案とビデオ画像の移動物体のリアルタイム追跡,情報処理学会論文誌,Vol.44, No.8, pp.2244-2254,(2003)
- 山田弘幸,倉爪 亮,村上剛司,長谷川勉,LevelSetTrackingを用いた複数レーザレンジファインダとカメラによる歩行者のトラッキング,第12回ロボティクスシンポジア講演会予稿集,289, (2007.3).
- 山田 弘幸,倉爪 亮,村上 剛司,長谷川 勉,ロボットタウンの実証的研究 -Level Set Trackingと複数レーザレンジファインダを用いた複数対象の同時追跡-,第24回日本ロボット学会学術講演会講演予稿集,,2N16,(2006.9)
- 小船 博行, 村上 剛司, 倉爪 亮, 長谷川 勉, ロボットタウンの実現に向けて -分散ビジョンによるロボットと人の行動計測-, 日本機械学会ロボティクスメカトロニクス講演会, 2P1-E11, (2006 5)
- 辻 徳生,Jasnoch Collin,倉爪 亮,長谷川 勉,Tracking Multiple Objects Using the Fast Level Set Method,日本機械学会ロボティクス・メカトロニクス講演会'04講演論文集, 2P2-L1-48, (2004).
- 辻,由井,倉爪,長谷川,Selective Fast Narrow Band 法の提案とカメラ画像上の移動物体実時間追跡,日本機械学会ロボティクス・メカトロニクス講演会'03講演論文集, 2P1-1F-D2, (2003).
Fast Level Set Methodとステレオカメラを用いたオクリュージョンに頑強なモーションキャプチャの構築
「Fast Level Set Method」を用いて,複数の重なり合う移動物体の実時間同時追跡を実現しています.
| 実際の動作 | キャプチャデータ |
| テクスチャマッピング | リアルタイムモーションキャプチャ |
発表論文
- Yumi Iwashita, Ryo Kurazume, Kenji Hara, Seiichi Uchida, Ken'ichi Morooka, and Tsutomu Hasegawa, Fast 3D Reconstruction of Human Shape and Motion Tracking by Parallel Fast Level Set Method, in Proc. IEEE International Conference on Robotics and Automation, pp.980-986, April 2008.
- 岩下 友美, 倉爪 亮, 原 健二, 内田 誠一, 諸岡 健一, 長谷川 勉, 並列Fast Level Set Methodによる移動体の高速な3次元形状復元, 電子情報通信学会論文誌, Vol.J90-D, No. 8, pp.1888-1899, (2007.8)
- Yumi Iwashita, Ryo Kurazume, Kenji Hara, and Tsutomu Hasegawa, Robust 3D Shape Reconstruction against Target Occlusion using Fast Level Set Method, Proc. The Second Joint Workshop on Machine Perception and Robotics, CD-ROM, 2006.
- Yumi Iwashita, Ryo Kurazume, Tokuo Tsuji, Kenji Hara, and Tsutomu Hasegawa, Fast implementation of level set method and its realtime applications,in Proc. IEEE International Conference on Systems, Man and Cybernetics 2004, pp.6302-6307, 2004.
- 岩下 友美, 倉爪 亮, 原 健二, 長谷川 勉, 局所境界の移動方向予測値に基づく実物体の高速な3次元形状復元, 第7回計測自動制御学会システムインテグレーション部門講演会講演予稿集, pp.914-915, 2006.12
- 岩下 友美, 倉爪 亮, 原 健二, 長谷川 勉, 境界移動予測に基く並列Fast Level Set Methodの計算負荷均衡化, 画像の認識理解シンポジウム (MIRU2006), IS1-31, (2006 7)
- 岩下 友美, 倉爪 亮, 原 健二, 長谷川 勉, 並列Fast Level Set Methodによる実物体の高速な3次元形状復元, 日本機械学会ロボティクスメカトロニクス講演会, 2P1-C13, (2006 5)
- 岩下 友美,倉爪 亮,辻 徳生,原 健二,長谷川 勉,Fast Level Set Methodを用いた複数移動物体の実時間計測システム,画像の認識・理解シンポジウム (MIRU 2004), pp.267-272,(2004 7)
- 岩下 友美,倉爪 亮,辻 徳生,原 健二,長谷川 勉,FLSMを用いた隠れに頑強なモーションキャプチャの開発,日本ロボット学会学術講演会講演予稿集,(2004).
- 岩下 友美,山崎 智弘,倉爪 亮,長谷川勉,Fast Level Set MethodのPCクラスタへの実装,日本機械学会ロボティクス・メカトロニクス講演会'04講演論文集, 2P1-H-46, (2004).
- 岩下 友美,倉爪 亮,辻 徳生,原 健二,長谷川 勉,Fast Level Set Methodを用いた複数移動物体の実時間追跡,第9回ロボティクスシンポジア講演会予稿集,5B1, (2004)
- 岩下 友美,倉爪 亮,辻 徳生,原 健二,長谷川 勉,Fast Level Set Methodを用いた人体の2次元,3次元リアルタイム追跡,計測自動制御学会システムインテグレーション部門講演会論文集,pp.662-663,(2003)
- 岩下 友美,倉爪 亮,辻 徳生,原 健二,長谷川 勉,Fast Level Set Methodを用いた3次元人体形状の実時間計測システムの構築,情報処理学会コンピュータビジョンとイメージメディア(CVIM)研究会,CVIM-141-18,(2003)
幾何学的拘束を利用したテクスチャマッピング
九州大学芸術工学科 原健二准教授と共同で,幾何学的拘束を利用したテクスチャマッピングの研究を行いました. 通常のテクスチャマッピングでは3次元モデルを2次元画像に重ねて位置合わせを行いますが, この手法は逆に2次元画像を3次元モデルに重ね合わせ,投影された画像エッジの3次元空間での平行性,直交性を利用して 位置合わせを行います.
| 2D-3Dアラインメント | 位置合わせ結果 |
発表論文
- 椛島 佑樹, 原 健二, 倉爪 亮, 岩下 友美, 諸岡 健一, 内田 誠一, 長谷川 勉, 逆投影と幾何拘束を用いた2D/3D位置合わせ, 電子情報通信学会論文誌, 掲載決定, (2008)
- Yumi Iwashita, Kenji Hara, Yuuki Kabashima, Ryo Kurazume, Tsutomu Hasegawa, Robust 2D-3D alignment based on geometrical consistency, The 6th International Conference on 3-D Digital Imaging and Modeling (3DIM2007), August 2007.
- 山田 毅, 原 健二, 倉爪 亮, 岩下 友美, 長谷川 勉, 透視投影因子分解法を用いた鏡面球映りこみ像の3次元形状推定, 日本機械学会ロボティクスメカトロニクス講演会, 2P2-B22, (2008.6)
- 椛島 佑樹, 原 健二, 倉爪 亮, 岩下 友美, 長谷川 勉, 幾何学的整合性を用いた初期位置に頑強な2D/3D位置合わせ, 第7回計測自動制御学会システムインテグレーション部門講演会講演予稿集, pp.1334-1335, 2006.12
- 椛島 佑樹, 原 健二, 倉爪 亮, 岩下 友美, 長谷川 勉, 幾何学的整合性を用いたテクスチャのアライメント, 画像の認識理解シンポジウム (MIRU2006), IS2-17, (2006 7)
- 椛島佑樹,原 健二, 倉爪 亮,岩下友美,長谷川勉,幾何学的整合性に基づくレンジデータとカラー画像の位置合わせ,情報処理学会コンピュータビジョンとイメージメディア(CVIM)研究会,CVIM-153-5,(2006.3)
冗長性を利用した移動マニピュレータのVisual Servo
冗長自由度を利用したビジュアルサーボシステムを開発し,Stanford大の移動マニピュレータ Samm に実装しました.
| 冗長自由度トラッキング | 冗長ビジュアルサーボ |
発表論文
RGB-Dカメラおよびレーザースキャナを用いた空間識別
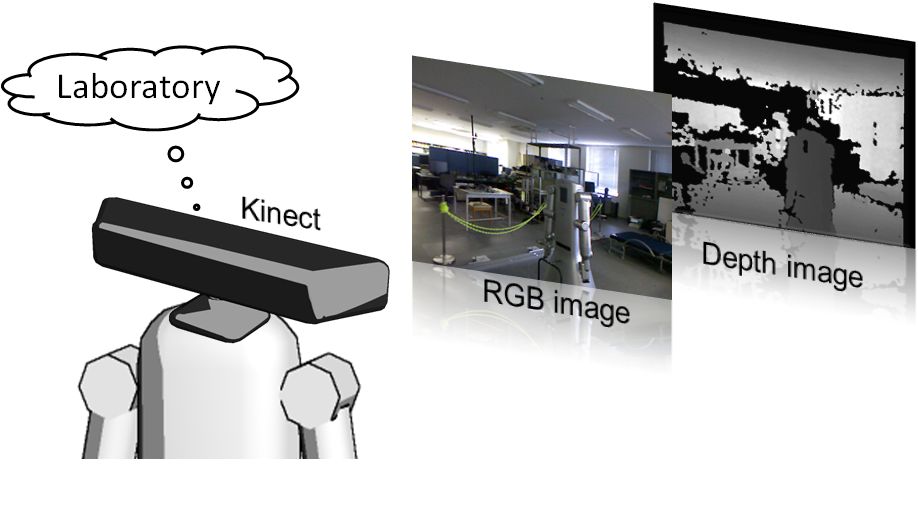
Microsoft Kinectやレーザースキャナを用いた,画像と距離情報を統合した空間識別手法を開発しています. 開発した手法は,センサから得られる距離情報,画像情報から画像特徴量を抽出し,機械学習の手法を適用して, 屋内であれば台所,居間,廊下など,屋外であれば駐車場,住宅街,都市部などの周囲の環境を識別します. 開発した手法は,サービスロボットによる周囲環境認識のみならず,状況に応じた安全な自動運転技術の実現にも利用できます.
| Kinectを用いた空間識別 |
|---|
 |
データベース
corridors(255 Mbyte, 5 categories) 
|
genkiclub_f3_corridor_01, genkiclub_f4_corridor_01, w2_10f_corridor_01, w2_7f_corridor_01, w2_9f_corridor_02 |
kitchens(204 Mbyte, 8 categories) 
|
genkiclub_f3_kitchen_01, genkiclub_f3_kitchen_02, w2_10f_kitchen_01, w2_10f_kitchen_09, w2_9f_kitchen_01, w2_9f_kitchen_02, w2_9f_kitchen_10, w4_6f_kitchen_01 |
labs(583 Mbyte, 4 categories) 
|
hasegawa_lab, kurazume_lab, taniguchi_lab, uchida_lab |
offices(95 Mbyte, 3 categories) 
|
hasegawa_office, kurazume_office, morooka_office |
studyrooms(328 Mbyte, 8 categories) 
|
w2_2f_studyroom_01, w2_2f_studyroom_02, w2_2f_tatamiroom_01, w2_2f_tatamiroom_02, w4_2f_studyroom_01, w4_2f_studyroom_02, w4_2f_tatamiroom_01, w4_2f_tatamiroom_02 |
toilets(116 Mbyte, 3 categories) 
|
w2_10f_toilet_01, w2_2f_toilet_01, w2_9f_toilet_01 |
発表論文
- Hojung Jung, Oscar Martinez Mozos, Yumi Iwashita, Ryo Kurazume, Local N-ary Patterns: a local multi-modal descriptor for place categorization, Advanced Robotics, Vol. 30, No. 6, pp.402--415, 2016, doi:10.1080/01691864.2015.1120242
- Hojung Jung, Oscar Martinez Mozos, Yumi Iwashita, Ryo Kurazume, The Outdoor LiDAR Dataset for Semantic Place Labeling, The 2015 JSME/RMD International Conference on Advanced Mechatronics (ICAM2015), Tokyo, Dec. 12.5-8, 2015
- Oscar Martinez Mozos, Hitoshi Mizutani, Hojung Jung, Ryo Kurazume, Tsutomu Hasegawa, Categorization of Indoor Places by Combining Local Binary Pattern Histograms of Range and Reflectance Data from Laser Range Finders, Advanced Robotics, Vol.27, No.18, pp.1455?1464, 2013
- Oscar Martinez Mozos, Hitoshi Mizutani, Ryo Kurazume, Tsutomu Hasegawa, Categorization of Indoor Places Using the Kinect Sensor, Sensors, Vol. 12, No. 5, pp.6695-6711, 2012
- 鄭 好政, モゾスオスカル マルティネス, 岩下 友美, 倉爪 亮, RGB-Dセンサによる距離と濃淡画像のLBP共起性を利用した空間識別, 第33回日本ロボット学会学術講演会, 1B2-07, 2015.9.3-5
- 大音 雄輝, 鄭 好政, 岩下 友美, 倉爪 亮, 全周距離画像を用いた屋外環境の種別推定, 第33回日本ロボット学会学術講演会, 2B1-06, 2015.9.3-5
- 鄭 好政, モゾスオスカル マルティネス, 岩下 友美, RGB-Dセンサによる距離と濃淡画像のLBP共起性を利用した空間識別, 日本ロボット学会学術講演会, 1B2-07, 2015.9.3-5
- 大音 雄輝, 鄭 好政, 岩下 友美, 倉爪 亮, 全周距離画像を用いた屋外環境の種別推定, 日本ロボット学会学術講演会, 2B1-06, 2015.9.3-5
- 鄭 好政, 岩下 友美, Oscar Martinez Mozos, 倉爪 亮, 2次元Local Ternary Patternを用いたレーザスキャナによる屋外種別推定, 第32回日本ロボット学会学術講演会, 2J2-02, 2014.9.5
- Hojung Jung, Ryo Kurazume, Yumi Iwashita, Outdoor Scene Classification Using Laser Scanner, Proc. The Ninth Joint Workshop on Machine Perception and Robotics (MPR13), K-P-06, Kyoto, 2012.10.31-11.1(Best Poster Session Award)
- 水谷 仁, マルティネス モゾス オスカル, 大石 修士, 倉爪 亮, 岩下 友美, 長谷川 勉, 全周距離・反射率画像を用いたレーザスキャナによる空間種別の多数決識別, 日本機械学会ロボティクスメカトロニクス講演会2013, 2A1-J08, 2013.5.22~25
- 水谷 仁, Oscar Martinez Mozos, 倉爪 亮, 岩下 友美, 長谷川 勉, レーザ距離画像と反射率画像を用いた屋内環境のカテゴリ識別, 第30回日本ロボット学会学術講演会, 3M1-4, 2012.9.19
- 水谷 仁, マルティネスモゾス オスカル, 倉爪 亮, 岩下 友美, 長谷川 勉, RGB-Dカメラを用いた屋内環境のカテゴリ識別, 画像の認識理解シンポジウム (MIRU2012), IS2-56, 2012.8.7
- 水谷 仁, マルティネス モゾ スオスカル, 倉爪 亮, 岩下 友美, 長谷川勉, RGB-D カメラを用いた屋内環境のカテゴリ識別, 第17回ロボティクスシンポジア講演予稿集, pp.461-468, 2012.3.15
- マルティネス モゾスオスカル, 水谷 仁, 蔡 現旭, 倉爪 亮, 長谷川 勉, 距離画像を用いた空間のカテゴリー識別, 第29回日本ロボット学会学術講演会, 1O1-5, 2011.9.7
- マルティネス モゾス オスカル, 水谷 仁, 倉爪 亮, 岩下 友美, 長谷川 勉, 距離・画像情報を統合したロボットのための屋内環境のカテゴリ識別 コンピュータビジョンとイメージメディア(CVIM), Vol.2012-CVIM-180, No.29, 2012,1,19
Previewed Reality -未来の可視化システム-
本研究では,近未来に起こり得る出来事を自分の目で知覚できるPreviewed Reality を開発しています.本システムは情報構造化環境,没入感ゴーグルディスプレイ,光学式トラッカー,動力学シミュレ ータなどからなります.情報構造化環境には多数のセンサが設置され,物体や人間,ロボットの位置情報を常にデー タベースへ登録しています.ゴーグルの位置は光学式トラッカーにより計測され,動力学シミュレータで次時刻の 事象を予測し,近未来の仮想画像を合成します.合成された画像はAR技術により実画像へ重畳され,装着者へ提示 されます.本システムにより,危険な状況を事前に直観的に提示でき,人間とロボットが安全に共存できます.
| Previewed Reality | Previewed Reality |
| Previewed Reality 1.0 and 2.0 | |
| Smart Previewed Reality | |
発表論文
- Asuka Egashira, Yuta Horikawa, Takuma Hayashi, Akihiro Kawamura, and Ryo Kurazume, Near-future perception system: Previewed Reality, Advanced Robotics, Vol., No., pp.-, 2020, DOI:
- Yuta Horikawa, Asuka Egashira, Kazuto Nakashima, Akihiro Kawamura, Ryo Kurazume, Previewed Reality: Near-future perception system, 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2017), Vancouver, Canada, 2017.9.24-28, pp.370-375, 2017
- 江頭 飛鳥, 今井 将人, 河村 晃弘, 倉爪 亮, Previewed Reality 2.0: 近未来可視化システム -透過型ディスプレイHoloLens を用いたシステム構築と衝突回避実験-, 日本機械学会ロボティクスメカトロニクス講演会2019, 2P2-D10, 2019.6.5-8
- 江頭 飛鳥, 堀川 雄太, 河村 晃宏, 倉爪 亮, Previewed Reality情報構造化空間における近未来可視化システム, 第36回日本ロボット学会学術講演会, 3D1-05, 2018.9.5-7
- Yuta Horikawa, Asuka Egashira, Kazuto Nakashima, Akihiro Kawamura, Ryo Kurazume, Previewed Reality: Near-future perception system, Proc. The 13th Joint Workshop on Machine Perception and Robotics (MPR17), , Peking, 2017.10.16-17
- 堀川 雄太, 中嶋 一斗, 河村 晃宏, 倉爪 亮, Previewed Reality 情報構造化空間における近未来可視化システム -没入感ディスプレイを用いたシステム構築と実験-, 日本機械学会ロボティクスメカトロニクス講演会2017, pp.2A1-I07, 2017.5.10-13
- 堀川 雄太, 河村 晃宏, 倉爪 亮, Previewed Reality 情報構造化空間における近未来可視化システム, 第34回日本ロボット学会学術講演会, pp.1A1-08, 2016.9.7
第4人称センシング・第4人称キャプショニング
「第4人称センシング」「第4人称キャプショニング」とは, ユーザ,ロボット,環境の3つの視点(3つの人称)の情報を統合し, ユーザ周囲の状況をより正確に理解しようとする手法です. 「第4人称」とは,例えるなら,小説を読む「読者の視点」です. 読者は,主人公の感情や状況,相手の感情や状況,その他の登場人物の感情や状況など, 通常は知り得ない全ての情報を知ることができます(いうなれば「神の視点」). 「第4人称センシング」「第4人称キャプショニング」では, まるで全てを知り得る読者の視点のように,あらゆる人称からの情報を統合して, 包括的に状況を理解します.
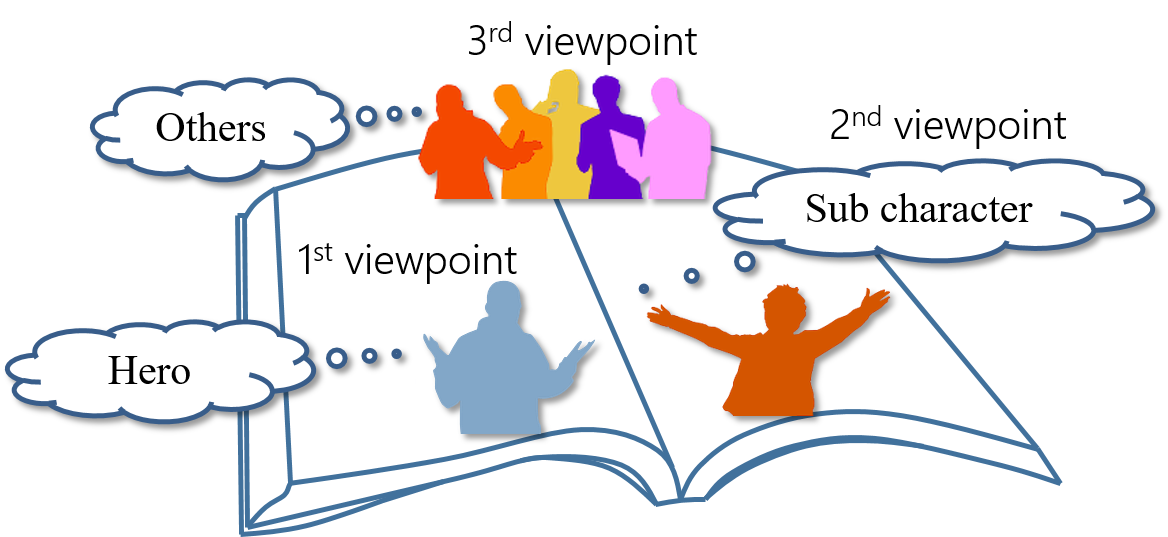 第4人称センシング
第4人称センシング |
 第4人称キャプショニング
第4人称キャプショニング |
発表論文
- Kazuto Nakashima, Yumi Iwashita, Akihiro Kawamura, Ryo Kurazume, Fourth-person Captioning: Describing Daily Events by Uni-supervised and Tri-regularized Training, The 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC 2018), Miyazaki, 2018.10.7-10
- Kazuto Nakashima, Yumi Iwashita, Yoonseok Pyo, Asamichi Takamine, Ryo Kurazume, Fourth-Person Sensing for a Service Robot, Proc. of IEEE International Conference on Sensors 2015, pp.1110-1113, 2015
- Yumi Iwashita, Kazuto Nakashima, Yoonseok Pyo, Ryo Kurazume, Fourth-person sensing for pro-active services, Fifth International Conference on Emerging Security Technologies (EST-2014), pp.113-117, 2014
- Kazuto Nakashima and Ryo Kurazume, Describing Daily Events in Intelligent Space via Fourth-person Perspective Images, Proc. The 14th Joint Workshop on Machine Perception and Robotics (MPR18), PS2-1, Fukuoka, 2018.10.16-17/li>
- 中嶋 一斗, 岩下 友美, 倉爪 亮, 第四人称視点に基づく情報構造化空間の状況説明文生成,第36回日本ロボット学会学術講演会, 2C1-03, 2018.9.5-7
- 中嶋 一斗, 岩下 友美, ピョ ユンソク, 高嶺 朝理, 倉爪 亮, サービスロボットのための第4人称センシングの提案, 画像の認識理解シンポジウム (MIRU2015), pp.SS4-11, 2015.7.28-30
- 中嶋 一斗, 岩下 友美, ピョ ユンソク, 高嶺 朝理, 倉爪 亮, サービスロボットのための第4人称センシングの提案, 日本機械学会ロボティクスメカトロニクス講演会2015, pp.1A1-O03, 2015.5.18