KURAZUME AND KAWAMURA LABORATORY : REAL-WORLD INFORMATIVE ROBOTICS Faculty of Information Science and Electrical Engineering, Kyushu University
日本語
English
HOME
Research
Publications
About Lab
News & Topics
2024年3月26日
Mr. Nishiura made a speech as a representative of graduating students at the degree conferment ceremony.
2024年3月25日
11 students have graduated from the laboratory.
2024年1月24日
Mr. Uno received SICE SI2023 Excellent Presentation Award.
2024年1月24日
Mr. Nishiura received SICE SI2023 Excellent Presentation Award.
2024年1月24日
Mr. Hyodo received SICE SI2023 Excellent Presentation Award.
2024年1月17日
Mr. Nishiura received IEIEJ Kyushu Branch Excellent Presentation Award.
2023年12月1日
Mr. Nishiura received IEIEJ Excellent Presentation Award.
2023年10月20日
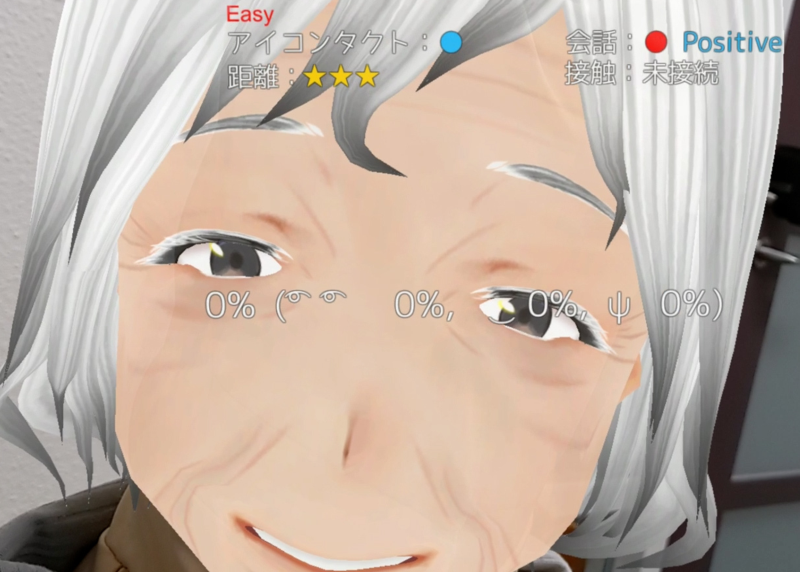
Humanitude dementia-care training system, HEARTS, is introduced in Zaikai Kyushu.
2023年9月18日
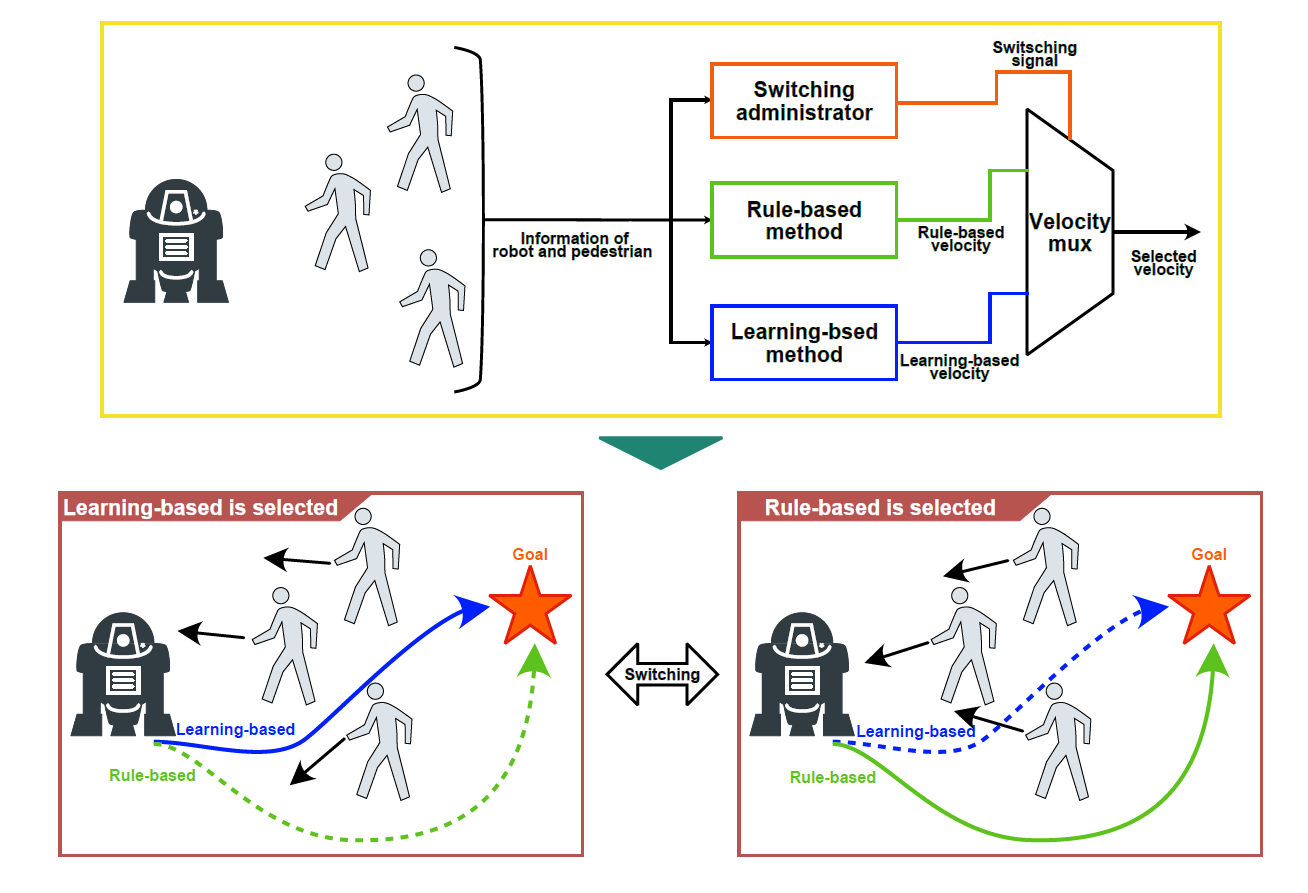
We are accepted for SIP (Cross-ministerial Strategic Innovation Promotion Program).
2023年8月30日
Humanituide dementia-care training system, HEARTS, is introduced in Nikken BP.
Backnumbers